主页 > 苹果版imtoken图标 > 比特币交易所地址识别方法、系统、装置及流程
比特币交易所地址识别方法、系统、装置及流程
本发明属于信息技术和安全技术领域,具体涉及一种比特币交易地址识别方法、系统及装置。
背景技术:
2008年金融危机期间,各国为应对危机出台了宽松的货币政策,主权货币的信用跌至冰点,使得以国家信用为基础的中心化货币体系不再那么可靠。 比特币就是这样诞生的。 它具有匿名和去中心化的特点。 它利用区块链技术构建公共票据,确保交易安全,控制新货币的诞生。 它已经引起了越来越多的人的关注。 但不法分子利用其匿名性进行非法交易,很容易逃避法律制裁。 最臭名昭著的是丝绸之路沿线的非法贩毒和跨国洗钱活动,监管部门难以监管和查处。
针对这种情况,目前主流的方法是反匿名炒作,主要包括以下两种解决方案:
方案一:通过收集比特币交易所等公开数据,实现比特币的反匿名性。部分比特币交易所会存储用户的比特币地址、身份信息等,部分支持比特币支付或接受比特币捐赠的服务机构会披露他们的比特币地址。 但涉及到隐私保护问题,需要政府和多方平台的支持,成本较高,无法大规模应用。
方案二:通过部署尽可能多的检测节点,监测获取比特币网络的交易信息和传输路径,实现对交易者信息的识别。 该方案在题为“一种比特币交易身份表示方法”的专利申请(申请号201710965814)中有具体描述。 该方案涉及部署大量探针,成本高,无法广泛应用,准确率无法保证。
综上所述,本发明的目的在于将反匿名问题转化为比特币交易地址的真实性识别问题。 比特币交易所作为比特币与法定货币的兑换平台,提供了虚拟货币与现实世界的唯一联系,在比特币交易体系中发挥着重要作用。 识别比特币交易网络中的交易所地址对于监管至关重要,通过它可以进一步分析感兴趣的交易和地址,并可以观察这些交易和地址加入和退出交易网络的时间,以及可能涉及的犯罪行为。进一步调查。 做出判断。
技术实现要素:
为了解决现有技术中存在的上述问题,即为了解决根据比特币交易信息判断输入的地址信息是否为兑换地址的问题,本发明的第一方面提出了一种方法用于识别比特币交易地址的方法包括:
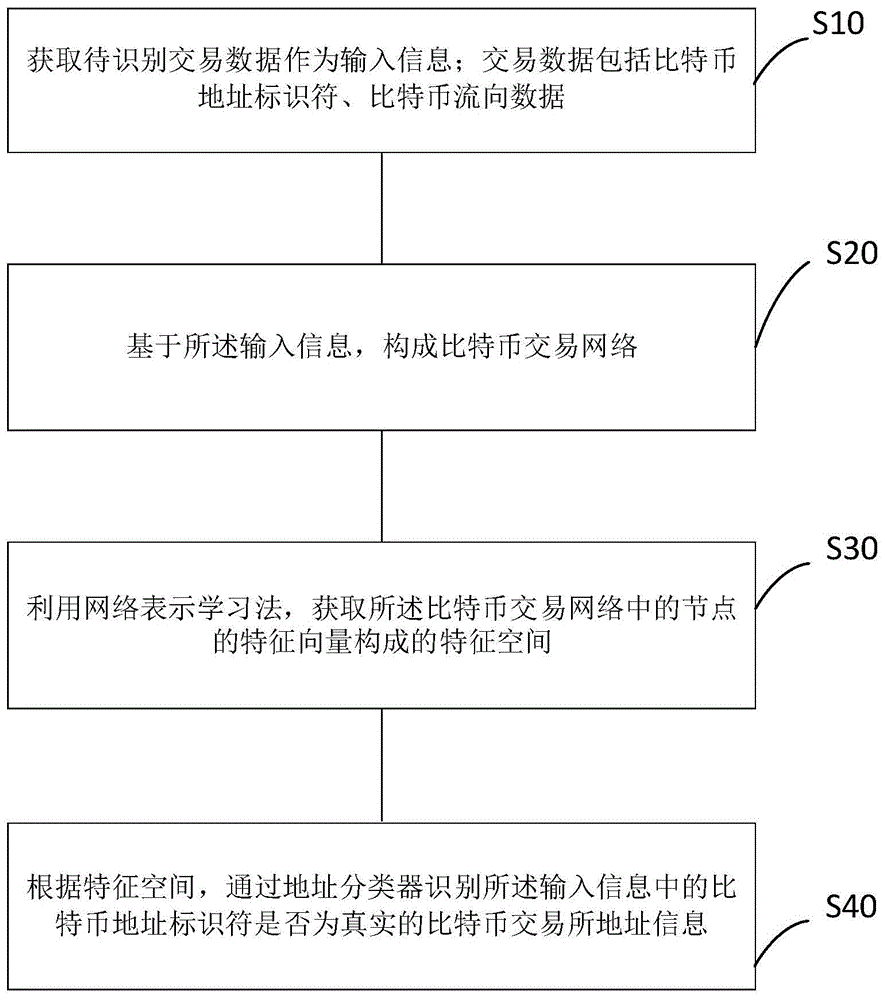
步骤s10,获取待识别为输入信息的交易数据; 交易数据包括比特币地址标识和比特币流量数据;
步骤s20,根据输入的信息形成比特币交易网络;
步骤s30,利用网络表示学习方法得到比特币交易网络中节点的特征向量构成的特征空间;
步骤s40,根据特征空间,通过地址分类器识别输入信息中的比特币地址标识是否为真实的比特币交易所地址信息;
在,
地址分类器是基于多个映射函数的分类器模型的组合,映射函数的分类器模型包括线性支持向量机模型、二项逻辑回归模型、决策树模型和随机森林模型中的一种或更多的; 多个映射函数模型的输出通过多数表决的方法选出作为地址分类器的输出。
在一些优选的实施方式中,在比特币交易网络中,以交易地址为节点,以比特币在同一交易中地址之间的流向关系为边。
在一些优选的实施方式中,步骤s30“利用网络表示学习方法获取比特币交易网络中节点的特征向量形成的特征空间”,方法为:
对于比特币交易网络的每个节点,采用截断随机游走策略生成一组游走序列;
使用skip-gram模型训练随机游走序列,通过最大化每个游走序列节点生成邻居节点的概率得到每个节点的向量表示,进而得到比特币交易网络的特征矩阵,并用这个矩阵作为比特币交易网络的特征空间。
在一些优选的实施方式中,地址分类器的训练方法为:
获取训练样本; 训练样本包括交易数据样本和标签样本; 交易数据样本是比特币地址标识和比特币流量数据的集合,标签样本是判断交易数据样本中的比特币地址标识是否为比特币兑换地址的标签;
通过步骤s20和s30对交易数据样本进行预处理,得到交易数据样本对应的特征空间样本;
地址分类器是根据特征空间样本和相应的标签样本进行训练的。
在一些优选的实施方式中,标签样本为一般节点时为-1,为交换地址对应的节点时为1。
在一些优选实施例中,交易数据样本包括交易哈希值、交易时间戳数据、交易输入地址哈希值和交易输出地址哈希值。
在一些优选实施例中,“通过多数表决选择多个映射函数模型的输出作为地址分类器的输出”,方法为:
根据多个映射函数模型的输出类别,选择得票最多的类别,如果两个类别的得票数相同,则随机选择其中一个。
在本发明的第二方面,提出了一种比特币交易所地址识别系统,该系统包括获取模块、网络构建模块、特征提取模块和分类器预测模块;
获取模块,用于获取待识别的交易数据作为输入信息; 交易数据包括比特币地址标识和比特币流量数据;
网络构建模块,用于根据输入信息构建比特币交易网络;
特征提取模型被配置为使用网络表示学习方法获得由比特币交易网络中的节点的特征向量组成的特征空间;
分类器预测模块用于使用地址分类器根据特征空间识别输入信息中的比特币地址标识是否为真实的比特币交易所地址信息。
在本发明的第三方面,提出了一种存储装置,其中存储有多个程序,程序的应用由处理器加载并执行,以实现上述的比特币兑换地址识别方法。
在本发明的第四方面,提出了一种处理装置,包括处理器和存储设备; 处理器适用于执行各种程序; 存储装置适合于存储多个节目。 该程序适合于由处理器加载并执行以实现上述比特币交易所地址识别方法。
本发明的有益效果:
本发明只需要根据比特币交易网络数据判断是否为交易所地址即可,比特币交易网络数据可以通过标有比特币数据的比特币区块链网站公开获取,或者通过比特币钱包网站下载。爬虫数据,本发明的比特币交易所地址识别技术依赖资源少,不需要采集或进行人工数据标注,适用范围广;
本发明采用网络表示学习方法提取特征,通过非监督机器学习方法自动学习网络的结构特征,得到网络中各节点的向量表示。 相比于传统利用节点的网络特征,如节点的入度/出度、子节点/兄弟节点/前驱节点的个数,无需人工提取特征,网络的结构特征可以更好的掌握;
通过本发明,根据比特币交易网络数据识别交易所地址,识别效果更好。
图纸说明
通过阅读参考附图做出的非限制性实施例的详细描述,本申请的其他特征、目的和优点将变得更加清楚。
图1是本发明一个实施例的比特币交易地址识别方法的流程示意图;
图2为本发明实施例中基于交易数据构建交易网络的示例图;
图3是根据本发明实施例的比特币交易地址识别系统的示意性框架图。
详细说明
为使本发明的目的、技术方案及优点更加清楚明白,下面将结合附图对本发明实施例中的技术方案进行清楚、完整地描述。 显然,所描述的实施例是本发明的部分实施例,而不是全部的示例。 基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
下面结合附图和实施例对本申请作进一步详细说明。 应当理解,此处所描述的具体实施例仅仅用以解释相关发明,并不用于限制本发明。 还需要说明的是,为便于说明,附图中仅示出了与相关发明相关的部分。
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
本发明的比特币交易地址识别方法,包括以下步骤:
步骤s10,获取待识别为输入信息的交易数据; 交易数据包括比特币地址标识和比特币流量数据;
步骤s20,根据输入的信息形成比特币交易网络;
步骤s30,利用网络表示学习方法得到比特币交易网络中节点的特征向量构成的特征空间;
步骤s40,根据特征空间,通过地址分类器识别输入信息中的比特币地址标识是否为真实的比特币交易所地址信息;
其中,地址分类器是基于多个映射函数的分类器模型的组合,映射函数的分类器模型包括线性支持向量机模型、二项逻辑回归模型、决策树模型和随机森林模型。 一项或多项; 通过多数表决的方式选择多个映射函数模型的输出作为地址分类器的输出。
为了更加清楚地描述本发明的比特币兑换地址识别方法,下面结合图2对本发明方法实施例中的各个步骤进行详细说明。 1.
步骤s10,获取待识别为输入信息的交易数据; 交易数据包括比特币地址标识和比特币流量数据。
在本实施例中,输入信息包括交易的哈希值、交易时间戳数据、交易输入地址的哈希值和交易输出地址的哈希值。
输入信息可以是一笔交易的数据,也可以是交易链中连续多笔交易的数据。 一笔交易的输出是另一笔交易的输入,反复形成交易链。
在步骤s20中,将根据输入信息形成比特币交易网络。
在比特币交易网络中,以交易地址为节点,以同一笔交易中地址间的比特币流转关系为边。 如图2所示,图2示例性地展示了从交易数据和交易所地址构建交易网络的过程。
图2中a示例性地展示了2011年5月1日在比特币交易网络上添加了两个发送地址和两个接收地址的交易示例,通过该交易的哈希值可以在相关比特中查到详细信息区块浏览器网站。 具体来说,右上角的时间表示交易加入区块链的时间,第一行的值是交易的标识符,是交易的唯一标识。 接下来,“1btc”及其相邻值(交易地址的哈希值)表示该地址发送了1个比特币。
图2a中,输入信息为待识别交易数据(标识符:f19fb7212bef80de028646261b5a318baba23d9f1ace5896cabf5bd7c9b65ab3)作为输入信息; 交易数据包括比特币地址标识符、比特币流量数据:
比特币交易地址标识是交易地址的唯一标识,包括:
1jfogt4kneavrqdmjzeabula33a4h9s8qx;
1ajiyir7dmrzle3375bmfhddynavpmuluu;
1jfogt4kneavrqdmjzeabula33a4h9s8qx;
1jfogt4kneavrqdmjzeabula33a4h9s8qx。
比特币流量数据包括交易金额和交易流量。 交易金额为图2a部分所示1btc、135btc、135.67btc、0.33btc,btc为比特币。 交易流程如图2的a部分所示:两个发送地址分别发送了1个比特币和135个比特币,两个接收地址分别收到了135.67个比特币(用于支付)和0.33个比特币(可能是交易手续费或新地址)剩余的比特币被存储)。
在图 2 中,b 是从比特币交易中提取的信息示例,其中箭头上的值表示流通中的比特币数量。 这里,ai 表示地址,ti 表示交易。 t1是向地址a1发送1个btc的交易,t2是向地址a2发送135个btc的交易。 t3 是具有两个输入(a1 和 a2)和两个输出(a3 和 a4)的事务,它于 2011 年 5 月 1 日添加到区块链。t4 是一个具有五个输入和两个输出(a5 和 a6)的事务发生在同一天。 其中,t4的两个输入(即a3和a4)是上一笔交易t3的输出;
交易网络代表比特币随时间在地址之间的流动。 图2中的c是基于图2中b中的信息构建的交易网络,其中节点代表交易地址,边代表同一笔交易中地址之间的比特币流转关系。 因为交易网络只有一个地址来发送/接收关于发送/接收了多少比特币的信息,并没有给出输入和输出之间比特币流量的具体值,因此,任何输入和输出之间都存在边缘同一笔交易的地址。
步骤s30,采用网络表示学习方法得到比特币交易网络中节点的特征向量组成的特征空间。
在本实施例中,首先采用截断随机游走策略为比特币交易网络的每个节点生成一组游走序列。 使用deepwalk算法(该方法是一种无监督的表示学习算法),通过掌握网络的拓扑信息生成每个节点的向量表示。 为了发现节点的分布,使用截断的随机游走策略来生成一组游走序列。 形式上,假设生成的随机游走序列中vi左右w的窗口中的序列为vi-w,...,vi-1,vi+1,...,vi +w。
然后,使用skip-gram模型训练随机游走序列,通过最大化每个游走序列节点生成邻居节点的概率得到每个节点的向量表示,进而得到比特币交易网络的特征矩阵, 和用这个矩阵作为比特币交易网络的特征空间。 作为简化,忽略了节点的顺序和与中心节点的距离。
本实施例中的deepwalk算法可以参考b.perozzi, r.al-rfou, ands.skiena, “deepwalk: online learning of social representations,” proceeding of the 20thacmsigkdd international conference on knowledge discovery and datamining, newyork,美国纽约,2014 年。此处不再详细描述。
步骤s40,根据特征空间,通过地址分类器识别输入信息中的比特币地址标识是否为真实的比特币交易所地址信息。
在本实施例中,地址分类器用于判断是否为比特币兑换地址的二元分类问题。 分类器将交易网络的节点分为两类,一类对应交易所地址,一类对应一般网络节点。 给定一个交易网络g=(v,e),节点集v为交易地址,边集e为地址间的比特币流通关系。 设gl=(v,e,x,y)是一个带标签的交易网络,x∈rv×d是基于网络表示学习生成的特征空间,d是每个特征向量的特征空间的大小,y是标签Set,其值为-1(一般节点)或1(交易所地址对应的节点)。 任务是学习从特征空间到标签集的映射函数 f:x→y。
本实施例中地址分类器需要预先训练,其训练方法为:
获取训练样本; 训练样本包括交易数据样本和标签样本; 交易数据样本为包括比特币地址标识和比特币流量的数据集合,标签样本用于判断交易数据样本中的比特币地址标识是否为比特币兑换地址的标签;
通过步骤s20和s30对交易数据样本进行预处理,得到交易数据样本对应的特征空间样本;
地址分类器是根据特征空间样本和相应的标签样本进行训练的。
在本实施例中,交易数据样本包括交易哈希值、交易时间戳数据、交易输入地址哈希值和交易输出地址哈希值。 当标签样本为一般节点时,标签为-1,当为交换地址时,标签为1。
学习映射函数的模型包括线性支持向量机、二项逻辑回归、决策树和随机森林中的一种或多种。 在本实施例中,优选四种模型的组合。
在训练过程中,通过以下(1)、(2)、(3)、(4)四个部分分别描述四种模型的训练方法。
(1)“线性支持向量机”模型的训练方式为:
根据训练集在样本空间中找到一个分离超平面,正确划分间隔最大的两类数据。 通过求解边缘最大化问题或相应的凸二次规划问题,得到分离超平面和分类决策函数。 在本实施例中,“线性支持向量机”模型可以参考c.cortesandv.vapnik,“support-vectornetworks,”machine learning,journalarticlevol.20,no.3,pp.273-297,september011995。 说。
(2) “Binomial Logistic Regression”模型的训练方法为:
转向条件概率分布问题,概率是参数化逻辑分布。 最大似然估计法用于估计模型参数,即以似然函数为目标函数的优化问题,梯度下降法和拟牛顿法通常用于求解模型参数。 在本实施例中,“二项逻辑回归”模型可以参考m.collins, reschapire, andy.singer, “logistic regression, adaboostandbregmandistances,” machinelearning, vol.48, no.1, pp.253-285, 2002/07 / 012002。这里没有进一步的细节。
(3)“决策树”模型的训练过程包括特征选择、决策树生成和决策树剪枝三个步骤。
特征选择的目的是选择能够对训练数据进行分类的特征。 特征选择的关键是它的基准。 选择基尼指数来定义数据集的纯度。 在候选属性集a中,选择划分后基尼指数最小的属性作为最优划分属性。
决策树的生成就是通过计算基尼指数,从根节点开始递归生成决策树。 即利用基尼指数不断选择局部最优的特征,将训练集划分为基本可以正确分类的子集。
决策树的剪枝就是对生成的决策树的过拟合问题进行剪枝,以简化学习到的决策树。 决策树的剪枝往往从生成树中剪掉一些叶子节点或叶子节点以上的子树,将其父节点或根节点作为新的叶子节点,从而简化生成的决策树。
在本实施例中,“决策树”模型可以参考jrquinlan,“induction of decision trees,”machine learning,journalarticle vol.1,no.1,pp.81-106,march011986。 这里没有给出进一步的细节。
(4)“随机森林”模型由多个推车(分类树和决策树)组成,其训练过程为:
步骤411,给定训练集s,测试集t,特征维度d;
确定参数:使用的小车数量t,每棵树的深度d,每个节点使用的特征数量f;
终止条件:节点上最小样本数s,节点上最小gini指数m;
步骤412,对于每棵树,从s中提取一个与s大小相同的训练集s(i),作为根节点的样本,从根节点开始训练;
步骤413,若当前节点满足终止条件,则将当前节点设为叶节点,叶节点的预测输出为当前节点样本集中编号最大的类型c(j) ,而概率p是c(j)当前样本集的比例。 然后继续训练其他节点。
如果当前节点不满足终止条件,则从d维特征中随机选取f维特征,不放回。 利用这个f维特征找到分类效果最好的一维特征k及其阈值th。 将当前节点上k维特征小于th的样本分到左节点,其余分到右节点。 继续训练其他节点。
步骤414,重复步骤412和413,直到所有节点都被训练或标记为叶节点;
步骤415,重复步骤412、413、414,直到训练完所有小车。
在本实施例中,“随机森林”模型可以参考a.cutler, drcutler, and jrstevens, “randomforests,” machinelearning, vol.45, no.1, pp.157-176, 2004。不再详述。
经过以上四种模型的训练,在识别过程中,
“线性支持向量机”模型:
对于某个实例,将其带入分类决策函数进行计算,结果就是该实例所属的类别。
二项式逻辑回归模型:
对于某个实例,分别计算属于正类和负类的条件概率分布,概率最大的类就是该实例所属的类。
“决策树”模型:
从根节点开始,测试实例的某个特征,根据测试结果将该实例分配给子节点接收比特币的地址,如此递归,直到到达叶节点,输出预测值。
“随机森林”模型:
步骤421,对于每棵树,从当前树的根节点开始,根据当前节点的阈值th,判断该实例是进入左节点(<th)还是进入右节点(>=th),直到到达某个叶节点,并输出预测值;
步骤422,重复步骤421,直到所有t棵树都有输出预测值,输出的是所有树中预测概率和最大的类,即对每个c(j)累加p。
通过以上四种模型得到分类结果后,根据多个映射函数模型的输出类别,选择得票最多的类别。 如果两个类别的票数相同,则随机选择其中一个。 本实施例采用多数表决的方式对上述四种模型的预测值进行表决。 预测值是得票最多的类别。 如果两个类别的票数相同,则随机选择其中一个。 如果类别为1,则This node为比特币兑换地址对应的节点,否则为一般节点,为后续安全应用提供准备。
通过本发明的测试,f1值可以达到85%以上,准确率可以达到80%以上,召回率可以达到85%以上,实验证明具有较好的识别效果。
本发明第二实施例的一种比特币交易所识别系统,如图3所示,包括:采集模块1、网络构建模块2、特征提取模块3、分类器预测模块4;
获取模块1,用于获取待识别的交易数据作为输入信息; 交易数据包括比特币地址标识、比特币流量数据;
网络构建模块2,用于根据输入信息构建比特币交易网络;
特征提取模型3,用于利用网络表示学习方法得到由比特币交易网络中节点的特征向量组成的特征空间;
分类器预测模块4用于使用地址分类器根据特征空间识别输入信息中的比特币地址标识是否为真实的比特币交易所地址信息。
本领域技术人员可以清楚地了解到,为描述的方便和简洁,上述系统的具体工作过程和相关说明可以参见签名方法实施例中的对应过程,在此不再赘述。 .
需要说明的是,上述实施例提供的比特币兑换识别系统只是对上述功能模块进行划分来举例说明。 在实际应用中,上述功能分配可以根据需要由不同的功能模块完成。 即对本发明实施例中的模块或步骤进行分解或组合。 例如,上述实施例中的模块可以合并为一个模块接收比特币的地址,或者进一步划分为多个子模块来完成上述全部或部分功能。 本发明实施例中所涉及的模块和步骤的名称仅用以区分各模块或步骤,并不构成对本发明的不当限定。
根据本发明第三实施例的一种存储设备,其中,存储有多个程序,所述程序适于由处理器加载并实现上述比特币交易地址识别方法。
根据本发明第四实施例的处理设备包括处理器和存储设备; 处理器适用于执行各种程序; 存储装置适合于存储多个节目。 该程序适合于处理器加载执行,以实现上述比特币交易所地址识别方法。
本技术领域的技术人员可以清楚地理解,为了描述方便和简单,上述存储设备和处理设备的具体工作过程和相关说明可以参考签名方法示例中的相应过程,在此不再赘述。在这里重复。 重复。
Those skilled in the art should be able to realize that the modules and method steps described in conjunction with the embodiments disclosed herein can be implemented by electronic hardware, computer software, or a combination of the two, and that the programs corresponding to the software modules and method steps Can be placed in random access memory (ram), internal memory, read-only memory (rom), electrically programmable rom, electrically erasable programmable rom, registers, hard disk, removable disk, cd-rom, or known in the technical field any other form of storage medium. In order to clearly illustrate the interchangeability of electronic hardware and software, the composition and steps of each example have been generally described in terms of functions in the above description. Whether these functions are performed by electronic hardware or software depends on the specific application and design constraints of the technical solution. Those skilled in the art may implement the described functionality using different methods for each particular application, but such implementation should not be considered as exceeding the scope of the present invention.
The terms "first", "second", etc. are used to distinguish similar items, and are not used to describe or represent a specific order or sequence.
The term "comprising" or any other similar term is intended to cover a non-exclusive inclusion such that a process, method, article, or apparatus/apparatus comprising a set of elements includes not only those elements but also other elements not expressly listed, or Also included are elements inherent in these processes, methods, articles, or devices/devices.
So far, the technical solutions of the present invention have been described in conjunction with the preferred embodiments shown in the accompanying drawings, but those skilled in the art will easily understand that the protection scope of the present invention is obviously not limited to these specific embodiments. Without departing from the principles of the present invention, those skilled in the art can make equivalent changes or substitutions to relevant technical features, and the technical solutions after these changes or substitutions will all fall within the protection scope of the present invention.
技术特点:
技术概要
The invention belongs to the field of information technology and security technology, and specifically relates to a bitcoin exchange address identification method, system, and device, aiming to solve the problem of judging whether the input address information is an exchange address based on bitcoin transaction information. The method includes: obtaining transaction data to be identified including bitcoin address identifiers and bitcoin flow data as input information; constructing a bitcoin transaction network based on the input information; using network representation learning to obtain the feature vector composition features of nodes in the bitcoin transaction network Space, and further use the address classifier to identify whether the bitcoin address identifier in the input information is a real bitcoin exchange address. The address classifier in the present invention is trained based on transaction data samples and label samples, and is a combination of classifier models based on multiple mapping functions. The invention relies on few resources and can directly identify the address of the exchange to achieve a better recognition rate.
Technical R&D personnel: Liang Jiaqi; Li Linjing; Zeng Dajun
Protected technology users: Institute of Automation, Chinese Academy of Sciences
Technology R&D Day: 2019.03.25
Technology Announcement Date: 2019.06.21




